CNN, Convolution
Convolutional Neural Network
Background
- 기존 다계층 신경망(MLP, multi-layered NN)의 문제점
- 입력데이터가 조금만 달라지더라도(이미지 크기 변화; 회전; 변형 등), 새로운 학습을 하기 않으면 좋은 성능이 나오지 않음
- 따라서 많은 raw data로 이루어진 학습 데이터를 매번 학습하기에는 많은 자원 및 시간 소요.
- Training Time; Network Size; Number of free parameters
- 종래 MLP는 입력 이미지의 모든 픽셀 값이 위치에 상관없이 동일 수준의 중요도를 갖는다고 전제함.
- 이러한 이미지에서의 공간적 데이터 특징(즉, local receptive field)을 무시하여 fully connected network을 이용할 경우, free parameter(즉, weight, bias)의 개수가 많아지고, overfitting 가능성이 높아짐.
- CNN에서는 visual cortex(시각 대뇌 피질)을 본따, 이미지 내의 픽셀들이 그 주변에 있는(즉, 공간적으로 인접한) 픽셀들과만 연관성이 높을 뿐(locality = local connectivity)이며, 그것을 느낄 수 있는 수용영역(receptive field)의 크기가 제한적이라는 점을 활용하고 있음.
- CNN이 갖는 특징
- 공간적으로 인접한 신호들에 대한 correlation 관계(locality)를 비선형 필터(=convolutional kernel)를 이용하여 추출
- 여러 개의 필터를 적용함으로써 다양한 local 특징(=feature map) 추출 가능
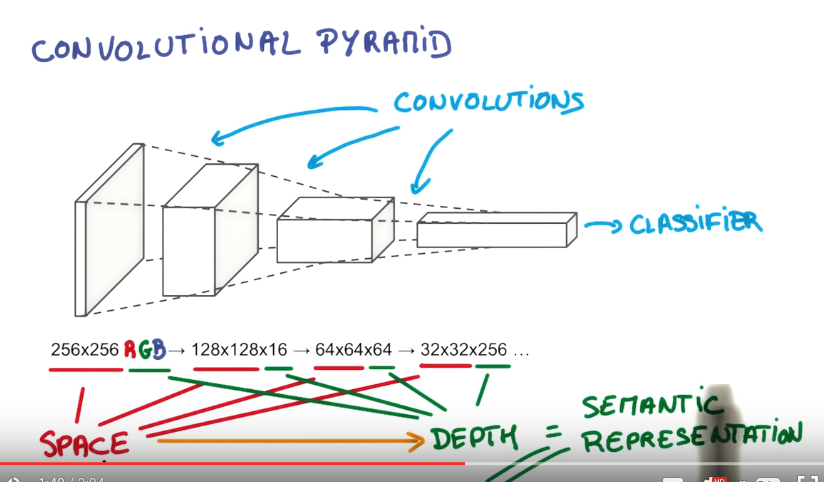
- Subsampling(pooling)을 통해 입력 데이터 크기를 줄여나감; 반복적인 필터링과 결합함으로써 global feature를 얻을 수 있음
- 이 때, 전체 입력에 대해 적용하는 free parameter(weight, bias) 공유를 통해 parameter 수를 줄여서 학습시간 및 overfitting을 낮춤
- 즉, 입력 데이터의 위상(topology) 변화에 무관한(또는 강인한) 항상성(invariance) 있는 특징(salient feature)을 도출할 수 있음.
- 그러나, CNN 역시 depth가 깊어지게 되면 다음의 문제를 겪게됨.
- vanishing/exploding gradient로 인해 학습 속도 떨어짐.
- 파라미터 수의 증가로 인한 overfitting 가능성 및 에러 발생 높아짐.
Concepts
Terms
- convolutional kernel = filter = patch
- receptive field
- 정보처리와 관계되는 세포에 대해 응답을 일으키는 자극의 영역. 외부 자극이 전체적인 영향을 주는 것이 아니라, 특정 영역에만 영향을 준다는 의미.
- ConvNet 관점에서 receptive field의 크기 = kernel의 크기 = w x h x d
Convolution
- 특정 시스템에 입력이 가해졌을 때 시스템의 반응이 어떻게 변하는지 해석하기 위한 용도; 이미지에서 특정 feature를 추출하기 위한 필터 구현시 사용됨.
- 참조 문헌
- 1x1 convolution
- C2개의 feature map을 그보다 적은 수의 C3개의 (즉, C2>C3) feature map으로 줄일 수 있어 다음 단계에서 처리해야 하는 파라미터 개수(=연산량)을 감소시킬 수 있음
- 단순한 matrix multiply를 적용할 수 있게 되어 더 빠른 계산 가능
CNN Basic
CNN hyper-parameter
- Filter = convolutional kernel
- 필터의 개수
- (시스템의 균형을 잡아준다는 의미에서,) 각 layer에서의 연산 시간/량을 일정하게 유지하는 방향: 각 layer의 연산 시간 = (pixel 개수) x (필터 개수) x (필터당 연산시간)
- 필터의 크기
- 입력 이미지가 큰 경우, (또는 첫번째 계층의 경우) 11x11, 15x15 등 큰 크기의 필터가 이용됨
- 32x32, 28x28 등 이미지의 경우 5x5가 주로 사용됨
- 큰 크기의 필터 1개 사용하는 것보다는 작은 크기의 필터 여러개를 중첩 사용하는 것이 낫다고 함.(즉, 7x7 1개 보다는 3x3 필터 3개 중첩이 낫다고 함): non-linearity에 대한 특징을 좀더 잘 찾아낼 수 있으며, 연산량도 더 적어지기 때문이라고 함.
- 필터의 stride
- convolution 수행 시 건너뛰는 픽셀의 수
- 입력 이미지의 크기가 클 경우, 연산량을 줄이기 위한 목적으로 입력 계층에 가까운 계층에 적용
- 일반적으로는 stride는 1로 둔 뒤, pooling을 통해 subsampling을 거치는 방식의 결과가 낫다고 함.
- zero-padding
- convolution 연산의 경우 경계 처리문제로 인해, 출력되는 feature map의 크기가 입력 이미지보다 작아지게 됨.
- 입력의 경계면에 0을 추가함으로써, convolution 후의 이미지 크기를 입력의 크기와 동일하게 유지할 수 있음.
- 또한 경계면의 정보까지 살릴 수 있음
Papers
- Backpropagation applied to handwritten zip code recognition (LeCun, 1989)
- CNN이 처음 소개된 논문; 필기체 Zip Code 인식을 위한 프로젝트에서 출발.
- Gradient-based learning applied to document recognition (LeCun; Bengio, 1998)
- CNN 구조(LeNet-5)를 설명
- 32x32 필기체 입력 데이터를 10개의 클래스로 분류
- Hierarchical neural networks for image interpretation (Behnke, 2003)
- Best practices for convolutional neural networks applied to visual document analysis (Simard, 2003)
- ImageNet Classification with Deep Convolutional Neural Networks (Krizehvsky; Hinton, 2012)
- Visualizing and understanding convolutional networks (2013)
- ZF Net
- CNN 특정 구조라기 보다는 (CNN 동작 구조를 이해하기 위한) deconvolution을 이용한 visualization 기법; 즉, CNN 중간 계층에서의 동작이 이미지 공간에서 어떻게 진행되었는지 mapping하여 가시화.
- max-pooling으로 인한 max-location에 대한 switch 정보 유지하여 un-pooling 문제 해결.
- Visualizing 기법 관련 후속 논문
- Return of the Devil in the Details: Delving Deep into Convolutional Nets (Chatfield, 2014)
- deepViz: Visualizing Convolutional Neural Networks for Image Classification (Bruckner, 2015)
Artifacts
ILSVRC
- ImageNet Large Scale Visual Recognition Challenge
- 이미지 인식 분야 성능 우열을 가리는 대회(2010~)
- image classification의 경우, 1000개 class별로 1000개 입력만 주어지므로 다양한 방식으로 이미지 데이터 개수를 늘리는 방식이 같이 고려됨.
- 3개 분야
- image classification: top-5 에러율(5개 후보 중 하나만 맞으면 맞는 것으로 인정)
- single-object localization: 물체가 존재하는 영역까지 파악. 최대 5개까지의 bounding box에서 ground truth와 50% 이상 영역이 일치하면 맞다고 봄
- object detection: 200 class 학습 데이터를 이용하여, 이미지에 존재하는 object를 가능한 많이 추정하되, false positive에 대해서는 감점을 주는 방식. mean Average Precision(mAP)로 결과를 평가.
- ImageNet: a very large dataset with lots of image categories
- 주요 우승자
- 2012: AlexNet (8 layers)
- 2013: ZF Net, OverFeat (5/6 layer)
- 2014: GoogleNet (22 layers), VGG (19 layers), SPPNet
- 2015: ResNet (152 layers)
- 2016: ResNeXt
- 2017: Xception, Stochastic depth&ResNet (1202 layers), DenseNet
CNN Frameworks (Image Classification)
- LeNet (LeCun)
- LeNet-1 (1990)
- 28x28 입력 이미지, convolution-subsampling-FC 연결 구조, 5x5 filter, max-pooling.
- 3000 free parameters (12만개의 free parameter가 필요한 종래 FC 구조에 비해 훨씬 적은 규모이며, 학습 결과도 낫다고 함)
- LeNet-5
- 32x32 입력이미지, filter 개수 늘어남, FC 크기 커짐.
- 6만 free parameters
- average-pooling
- 'AlexNet' (Krizehvsky; Hinton, 2012)
- Stride 개념(1단계 계층에서 stride 4를 이용함), Convolution-Convolution 연속 적용
- ReLU, DropOut, overlapped pooling, response normalization, data augmentation
- ReLU: sigmoid 및 tanh 함수에 비해 학습속도 빠르고(6배 정도), back-propagation 결과 단순; non-linear한 성질로 활성화됨; 입력의 normalization 불필요하지만, 출력된 결과를 pooling하기에 앞서서 normalization 필요(response normalization -> 강한 자극이 주변의 약한 자극 전달을 막는 효과; lateral inhibition)
- DropOut: voting 효과 및 co-adaption 회피 효과; FC 계층 처음 2개에만 50% 비율로 적용.
- overlapped pooling: 3x3 window를 stride 2로 사용했음. (일반적으로는 2x2 window를 사용해서 겹치지 않도록 건너뛸 경우, 이미지 크기의 가로/세로 각각 절반씩 총 1/4로 줄어든다.)
- data augmentation: 적은 연산으로 데이터 늘리기.
- 1) 256x256 원본 이미지에서 10개의 224x224 이미지 부분을 선택; 최종 결과에서는 softmax 출력 평균을 채택.
- 2) 원본 이미지의 컬러 RGB 값에 (PCA를 사용하여) 랜덤변수를 더하여 색상 변화
- GPU
- convolution layer: 전체 연산량의 90~95%, 파라메터 5%, data parallelism(여러 입력 feature map에 동일한 filter 연산 수행)에 적합
- fully connected layer: 연산량의 5~10%, 파라메터 95% (많은 파라메터로 인해 overfitting에 빠지기 쉬움), model parallelism에 적합
- 5개의 convolution, 3개의 FC layers, 중간중간의 max-pooling.
- 224x224x3 컬러이미지를 1000개 클래스로 분류
- 2개의 GPU (GTX580) 적용 고려한 병렬 구조
- 총 5개의 convolution 계층과 3개의 fully-connected 계층으로 구성.
- 65만개 nodes, 60M free parameters, 0.63B connections: 한번 학습하는 데 7일 넘게 소요.

- ‘Network in Network’ (Lin et al. (2013)
- Mlpconv 계층을 제안. 해당 계층 내에서 neuron 간의 복수의 layer를 가질 수 있다는 것을 제시.
- (CNN의 convolution layer가 local receptive field에서 linear feature를 추출하는 데 우수한 반면,) non-linear feature를 추출하기 위한 방안으로 featuremap 개수를 늘리는 종래 방식 대신, micro neural network을 설계하여, 종래 filter 대신 MLP를 이용한 convolution 방식을 제안함.
- (NIN으로 효과적인 feature 추출이 가능하므로) 최종 계층으로 FC 대신에 Global average pooling을 이용함.
- 1x1 convolution (=1 layer fully-connected neural network)
- 여러 개의 featuremap으로부터 비슷한 성질을 묶어내어, 결과적으로 차원을 줄이는(=연산량을 줄이는) 효과를 제공함.
- ZF Net (2013)
- (Visualizing 기법을 통해,) AlexNet의 hyper-parameter를 수정하여 성능 개선(3% 이상); convolution layer 크기를 확대.
- AlexNet에서는 일부 feature에 몰리거나, aliasing 문제도 발생하는 반면, ZFNet은 필터들에서 다양한 feature가 고르게 나타남.
- 1개의 GPU (GTX580)을 70 epoch, 12일간 학습.
- AlexNet의 첫번째 convolution 계층의 11x11 필터 (stride 4) 대신 7x7 필터 사용(stride 2).
- 필터의 크기가 작고 stride가 작게 설정될 때 결과가 낫다는 것을 확인함.
- 2개의 GPU에 인위적으로 다른 처리를 하는 시도가 불필요함을 보임.
- layer 별로 feature 습득 시간이 다름을 확인.
- 앞쪽 layer가 몇번의 epoch에 feature가 수렴되는 반면, 뒤쪽 layer는 40~50 epoch이 되어야 feature가 보이기 시작.
- 뒤쪽 layer로 갈수록 이미지 크기/위치변화/회전변화에 invariance 확보.
- GoogLeNet (Szegedy, 2014)
- (AlexNet에 비해 전체 망의 깊이는 깊어졌지만) Inception Module 개념 도입을 통해 전체 free parameter 수 감소(1/12) 가능: 9개의 인셉션 모듈 사용.
- AlexNet: 60M -> GoogLeNet: 5M
- (Inception: 남에게 어떤 생각을 주입하거나 생각을 읽어내는 개념을 차용하여), DNN을 이용하여 데이터로부터 중요한 정보를 얻어내는 것에 연상된 이름으로 판단됨.
- 동일 layer에 서로 다른 크기를 가진 convolution filter를 적용; 1x1 convolution을 이용하여, 차원을 줄였기(dimensionality reduction) 때문에 가능한 구조. (참고)

- auxiliary classifier (=SuperVision)
- 망이 깊어지면 vanishing gradient 이슈로 인해 학습 속도 저하 및 overfitting 문제가 발생한다.
- Re-LU 활성함수이용시, (sigmoid 또는 cross-entropy보다는 낫지만) 여전히 작은 값들이 곱해지다 보면 0 근처로 수렴되는 상황이 나올 수 있음.
- 학습을 위한 도우미로서 'reguarizer'와 같은 역할; auxiliary classifier가 batch-normalize되었거나 drop-out layer를 가질 경우, 최종 계층의 classifier 결과가 향상된다고 함.
- factorizing convolutions
- 커다란 크기의 filter(=convolution kernel)를 여러 계층의 작은 크기 filter로 대체하여 연산량 절감 가능.
- 5x5 convolution을 2단의 3x3 convolution으로 구현할 경우 25개의 free parameter를 18개로 대체하므로 28%의 연산 절감이 가능하다고 함; 같은 방식으로 7x7을 3단의 3x3으로 구현시 49 -> 27 (45% 절감).
- 3x3을 1x3과 3x1로 분해할 경우, 9 -> 6 (33% w절감).
- Testing
- 하나의 테스트 이미지(256x256)를 4개 크기로 변화시킨 뒤, 3개씩의 정사각형 부분을 선택하여, 6장의 224x224 크기를 선택하여 좌우반전 --> 4x3x6x2 = 144개의 이미지 생성하여 voting 결과를 이용.
- VGGNet (Simonyan, 2014)
- Oxford
- 3x3 convolution, 2x2 max pooling 으로 구성된 (GoogLeNet 보다) 단순한 구조
- (AlexNet에서의 커다란 필터를 사용하는 대신) 균일한 크기의 3x3 filter로만 receptive field를 설정함.
- depth가 성능에 어떤 영향을 주는 지 확인하기 위한 6개의 구조를 살펴본 결과 (ILSVRC-2012 데이터의 경우에는) depth 16에서 최적의 결과가 나오는 것을 확인
- 메모리와 파라미터 개수(133M ~ 144M)가 많이 필요하다는 것(그리고, GoogLeNet의 3배 연산량 소요)이 단점; 대부분의 파라미터(122M)는 FC 계층 3개에서 발생함.

- 이슈
- Local Response Normalization(LRN)이 별 효과가 나타나지 않았다고 함.
- 1x1 convolution이 적용되기는 하지만, 차원을 축소하기 위한 목적보다는, 차원을 그대로 유지하면서, ReLU를 통해 추가적인 non-linearity를 확보하려는 목적.
- vanishing/exploding gradient 문제를 해결하기 위해, 구조A(11개 계층)의 학습 결과(특히, 앞의 4개 계층과 마지막 FC 계층)를 pre-training 모델로서 보다 깊은 계층을 가진 구조의 parameter 초기값 설정에 이용함.
- (다양한 크기의 이미지에 대응할 수 있도록) 학습 입력 이미지의 scale을 무작위로 변화한 뒤(scale jittering) 무작위로 224x224를 선택;
- 테스트 데이터에 대한 multi-crop data augmentation(1장 -> 150장) 기법과 dense evaluation 개념을 함께 적용하여 성능 개선 시도.
- 관련 논문
- Deep inside convolutional networks: Visualising image classification models and saliency maps (Simonyan, 2013)
- Understanding Deep Image Representations by Inverting Them (Mahendran, 2015)
- ResNet (He, 2015)
- Deep residual learning for image recognition (He, 2015)
- DNN의 계층이 adding 됨에따라(=network depth가 깊어질수록) 성능이 저하되는 현상에 대한 대응. -> x와 H(x) 간의 관계를 학습하기 보다는, x와 H(x)의 차이(residual)를 학습하도록.
- residual framework
- 깊어진 망에서도 쉽게 최적화가 가능함; 늘어난 깊이로 인해 정확도가 개선됨
- CNN의 depth를 100개 이상 깊게 늘리면서도 학습 효율을 떨어뜨리지 않는 방안 고민의 결과
- residual learning: 입력의 작은 움직임(residual)을 학습한다는 관점
- 몇 개의 layer를 건너 뛰면서, 입력과 출력이 연결(shortcut)되는 구조이므로 (파라미터가 늘어나는 것도 아니면서) 연산량 증가가 미미하면서도, forward/backward path가 단순해지는 효과.
- 152 layers, Top-5 오차율 3.57%
- classification, localization, detection 분야 모두 우승.
- GoogLeNet (오차율 6.7%)보다 성능 2배 개선
- 특징
- VGG Net 설계 구조 활용: 대부분 3x3 convolutional kernel 이용. 복잡도(연산량)를 줄이기 위해, max-pooling, FC, dropout을 최대한 배제함
- Feature map 크기가 절반으로 작아지는 경우, 연산량의 균형을 맞추기 위해 필터의 수를 2배로 늘림; Feature map 크기를 줄이기 위해서는 (pooling을 사용하는 대신) convolution에서의 stride 크기를 2로 취함.
- 2개의 convolution layer마다 shortcut connection 연결.
- 학습 초기 단계에서 residual net의 수렴 속도가 plain network 보다 빠름.
- 최종 결과 제출시 2개의 152 layer 결과를 조합한(또는 depth를 서로 달리하는 6개 모델을 이용한) ensemble 결과를 제출했다고 함.
- CIFAR-10에 대한 110/1202 계층에 대한 실험을 통해, 천 개 이상의 계층이 구성될 경우에도 어느 정도의 성능이 나오지만, 망의 깊이를 고려한 데이터 양의 부족으로 인한 overfitting 발생이 된 것으로 판단됨 --> Identity mappings in deep residual networks (He, 2016)에서 pre-activation 기법(=activation을 short-cut connection 앞쪽에 배치하여 regularization 효과 높임)을 통한 개선된 ResNet 방안 제시됨; identity skip connection (shorcut connection에 어떠한 변형도 가하지 않은 경우) 속도나 성능이 최적임을 확인.
- Faster R-CNN의 개념이 ResNet으로 다시 이어진다고 간주됨.
- bottleneck architecture
- 2단의 3x3 convolution 계층을 1x1 - 3x3 - 1x1 세 개의 계층(병목 형태 구조)로 변경하여, 연산량(연산시간)을 절감
- 참고: Deep Residual Networks with 1K Layers
- 1000 계층 pre-trained model 오픈소스 (Torch 기반)
- Google Inception
- 연산 비용을 늘리지 않으면서도 NN을 scale up 할 수 있는 방안을 탐구
- Rethinking the inception architecture for computer vision (Szegedy, 2015)
- inception 모듈 내에 convolution (최종 계층의 stride 2) 및 pooling (stride 2)을 나란히 배치한 뒤 concat하여, 효율성과 연산량을 절감. -> 학습모델스스로 어떤 convolution/pooling을 하는 게 좋은 결과가 나오는 지를 결정할 수 있도록 하자. 이때, 연산량이 늘어나는 문제를 해결하기 위해 1x1 convolution 적용해보자.
- 즉, 단순하게 pooling layer를 적용하는 것보다, convolution layer와 나란히 적용하는 게 효과적이라는 것을 확인
- Inception-V2 (2015)
- 42개 layer.
- Inception-V1에 BN(batch normalization)을 반영한 기본 모델.
- 'BN-Inception'
- 299x299x3 입력 지원; (종래 7x7 convolution을) 3단의 3x3 convolution으로 대체 및 convolution kernel 인수분해 방식 적용.
- batch-normalized auxiliary classifier 적용시 regularization 효과 극대화.
- Inception-V3
- 144개 multi-crop 데이터 적용.
- Inception-V2에 convolution factorization, label smoothing, auxiliary classifier, BN을 결합시킨 모델
- Inception-V4
- Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning (Szegedy, 2016)
- Stem (9 layers): 299x299x3 입력 이미지를 35x35x384의 feature map로 생성.
- 3가지 형태의 inception 모듈 (A, B, C), 2가지 형태의 reduction 모듈 사용.
- Inception-ResNet
- Inception 구조에 ResNet 개념 접목을 통해 ResNet 보다 성능이 좋다는 것을 보임; Inception-V3보다 학습속도도 빠름(=훨씬 적은 epoch에서 최적 성능 나타나기 시작)
- V1, V2: Stem에 적용된 layer 구조가 다름 (즉, V1의 stem은 단순 구조, V2의 stem은 inception-V4와 동일); ResNet-V2의 필터 개수가 더 많음.
- ResNet의 residual connection 구조에 1x1 convoluton을 적용하여 일부 변경.
- Inception-V4와 3개의 Inception-ResNet-V2 ensemble을 했을 때, Top-5 error 3.1%라고 함.
- ResNeXt
- Aggregated Residual Transformations for Deep Neural Networks (Xie; Girshick; He, 2017)
- convolution 빌딩 블록의 개수(=cardinality)를 늘려서 분류 정확도를 향상.
- depth 또는 channel 수를 늘리는 것보다 cardinality를 키우는 것이 낫다는 결과.
- bottlenet block에서 그룹별 convolution 구조를 이용하여 sparse한 연결이 이루어 질 수 있도록 했다고 함.
- Xeption
- extreme inception
- spation correlation (= width x height과 cross-channel correlation (=depth)을 독립적으로 다루도록 함. -> 즉, 종전방식 처럼 한번에 depth를 묶어서 보는 대신, 크기에 대한 convolution 먼저 한 뒤, depth convolution을 수행하는 방식을 제안.
- depthwiase separable convolution = depthwise convolution + pointwise convolution (=1x1 cross-channel convolution)
- DenseNet
- Densely Connected Convolutional Networks (Huang, 2016)
- 즉, layer가 순차적으로 연결될 뿐만 아니라 건너뛰면서 연결될 수 있도록 함.
- ResNet의 영향 및 stochastic depth 개념(저자의 다른 논문; ResNet을 1202계층까지 쌓았음)에서 영향을 받았음;
Object detection
- 배경
- 물체를 인식하기 위해서는 'feature extraction'과 'object classifier' 두 가지 기능이 갖추어져야 함.
- feature 추출: 종래에는 gradient 기반 vision 알고리즘(SIFT, HOG) 이용됨
- object 검출: SVM, DPM 이용됨.
- Regions with CNN features(=R-CNN)
- Rich feature hierarchies for accurate object detection and semantic segmentation (Girshick, 2014)
- (AlexNet, 2012) classification 결과를 참고하여, detection 분야에 CNN 적용
- 종래 이미지 low-level gradient 속성에 대한 인식 알고리즘(SIFT, HOG)에 비해 좋은 결과 도출.
- 입력 데이터로부터 2000개의 후보 영역(region proposal)을 생성(Selective Search) 한 뒤, warping(늘리기)/crop(잘라내기)을 사용하여 224x224 크기로 변형하여 CNN에 입력 후 CNN feature vector를 얻어냄; 이후 linear SVM fitting을 이용하여 해당 영역을 분류(bounding box regressor)함
- Selective Search (Uijlings, 2013): segmentation의 장점과 exhaustive search 장점을 골고루 활용 (즉, segmentation을 통해 후보 영역의 seed를 설정한 뒤, 이를 기준으로 exhaustive search를 수행) ; 단순 정보(색상, texture) 뿐 아니라 내재된 계층 구조까지 활용하는 기법 (즉, 영상이 표현하고 있는 계층 구조를 통해 크기에 상관없이 대상을 찾아냄); 더불어 다양한 컬러 공간(RGB -> HSV[색상,채도,명도]) 이용; 개체 detection을 위한 후보 영역 검출을 위해 2013~2015 주목을 받다가, Faster R-CNN 등장 이후 인기가 감소함.
- Efficient Graph-Based Image Segmentation (Felzenszwalb, 2004): 의미있는 부분으로 효율적인 segmentation 수행; grid graph weighting, nearest neighbor graph weighting 제시.
- ILSVRC 데이터를 이용하여 CNN pre-training을 통해 파라미터 초기화한 뒤, PASCAL VOC(Visual Object Class)를 이용하여 fine tune 수행.
- detection 성능을 58%까지 끌어올림.
- 문제점
- 이미지 크기를 224x224 크기로 맞추기 위해 이미지 변형 및 손실이 발생하여 성능 저하 요인 존재.
- 2000개의 region proposal에 대한 순차적인 CNN 수행으로 인해, 학습 및 실행 시간이 많이 소요. --> 성능은 뛰어나나 속도가 느림; PASCAL VOC07 데이터 5천장 학습에 2.5일 소요 및 수백GB 저장 공간 요구; K40 GPU 이용했을 경우, Object detection 1장 수행에 47초 소요.
- region proposal, SVM 튜닝 등이 GPU 사용에 적합하지 않음
- 후속 연구로 Fast R-CNN (Girshick, 2015), Faster R-CNN (Ren; He; Girshick, 2015) 발표됨.
- Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition (=SPPNet) (He, 2014)
- AlexNet 구조에서, convolution layer는 sliding window로 인해 입력 크기에 영향을 받지 않으며, FC layer가 큰 영향을 받는다는 점에 주목.
- 입력 이미지를 crop/warp 하는 대신에, convolution의 결과를 spatial pyramid pooling을 수행하여 FC layer에 전달하는 방식을 이용; 즉, spatial bin으로 불리는 M개의 영역을 피라미드 방식으로 계산한 결과를 concatenation 시킨 뒤, 사전에 설정된 크기로 FC에 전달.
- Bag of Words (BoW) 개념: 특정 개체를 분류하는 있어, 굵고 강한 특징에 의존하는 대신, 여러개의 작은 특징을 사용하여 개체를 구별.
- 오직 1번만 convolution 과정을 거친 뒤, 피라미드 방식의 pooling을 수행하기 때문에, R-CNN에 비해 (학습 3배 빠르고, 실제 적용시는) 10~100배 빠른 성능을 보인다.
- Fast R-CNN (Girshick, 2015)
- 목표
- 검출 정확도(mAP)가 R-CNN/SPP Net보다 좋을 것; single-stage 학습 수행; 학습 결과를 모든 layer에 업데이트; feature caching을 위한 별도 저장 공간 불필요하도록.
- 특징
- 입력 이미지에 대한 ConvNet 연산 1회 수행을 통해 RoI pooling 계층(=Single-level pooling)에서 후보 영역을 뽑아낸 뒤 FC계층에 넣음.
- R-CNN/SPP Net에서 mini-batch를 128개(128장 이미지에서 하나씩 128개 RoI를 선택 = resion-wise sampling)로 수행했었으나, (원본 입력 이미지 크기에 대한 scale 처리를 따로 하지않는) Fast R-CNN에서는 hierarchical sampling 기법을 통해 2장의 이미지로부터 64개의 샘플을 뽑아 128개의 RoI를 정하도록 설정. --> 학습 과정에서 학습 결과를 공유할 수 있게되어 연산 속도가 빨라진다고 함.
- (PASCAL VOL 이미지 데이터에 대한) detection 성능이 70% 수준 근처까지 올라왔다고 함.
- 다음의 그림에서처럼, 출력부분의 softmax는 class를 구별하고, bbox regressor는 개체의 위치 정보를 구하는 역할을 수행한다.

- Faster R-CNN
- Faster R-CNN: Towards real-time object detection with region proposal networks (Ren; He; Girshick, 2015)
- 목적:
- Fast R-CNN이 종래 R-CNN에 비해, 이미지 처리 속도를 크게 향상시켰으나, test time에 (region proposal 고려시) 2초가 걸리는 것을 더욱 개선할 필요가 있음.
- (Region proposal을 위한 별도 과정을 거치는 대신에,) ConvNet에 region proposal을 위한 특수 용도의 네트워크(RPN)을 추가하였음; 즉, RPN에서 object가 있을만한 영역에 대한 proposal을 생성함.
- 특징
- Region proposal network: conv feature map에 대한 각각의 sliding window에서 scale과 aspect ratio를 달리하는 조합(=anchor)를 구하여 k개의 후보 영역을 지정하여 256/512 차원의 벡터 정보로 전달.
- 종래 Selective Search, Edge Box 방식의 후보영역 선택 방식에 비해 성능 개선이 가능하다고 함: 즉, VGG 프레임워크 기준으로, SS + Fast R-CNN에 약 2초가 소요된 반면, RPN + Fast R-CNN은 0.2초가 소요됨.
- 이후, Faster R-CNN의 기법은 ResNet이 object detection으로 적용됨에 있어 더욱 발전적으로 활용된다고 함.
- Network on Conv feature map (=NoC)
- Object Detection Networks on Convolutional Feature Maps (Ren; He; Girshick, 2016)
- CNN을 이용한 feature 추출 방법이 종래 computer vision 알고리즘에 비해 성능이 우수하다는 점을 이용하여, ResNet으로 구현 적용; Region proposal 및 RoI pooling 부분 역시 ConvNet으로 구현 가능.
- object classifier에 대한 부분을 NoC라고 명명하고, 어떻게 구현해야 최적의 성능이 나올 수 있는 지 실험을 통해 확인; FC 2~3개 만을 이용하는 종래 방식에 비해, Conv를 거쳐 maxout를 결합한 방식이 FC 앞쪽에서 들어올 경우 결과 개선이 가능하다는 것을 확인
- 특징
- ResNet의 Conv 계층 앞부분을 feature extractor로 활용하고, Conv 계층 후반부 및 Classifier를 Fast R-CNN 구조로 변형하고 구현함으로써, VGG-16(73.2%)을 사용했을 때보다 정확도 개선(76.4%).

- Mask R-CNN
- ResNeXt를 활용.
- RoIAlign 방식으로 후보영역 추출
- 클래스별 마스크 분리
single-object localization
- OverFeat
- OverFeat: Integrated Recognition, Localization and Detection using Convolutional Networks (Sermanet, LeCun, 2013)
- Testing
- multi-crop voting 방식(서로 겹치는 부분이 있더라도 ConvNet 연산을 전부 새롭게 해야함) 대신 dense evaluation 방식 이용.
- offset을 오밀조밀하게 구성한 non-overlapped pooling을 통해, resolution이 낮아지는 문제를 해결.
- 1-pass로 연산 가능한 구조
- 이후 등장한 SPP Net역시 1-pass 구조를 취하고 있으며, OverFeat의 성능과 속도에 크게 앞선 결과를 도출하였음.
- FC layer에 대한 해석 (by LeCun, 2015)
- = convolution layer with 1x1 convolution kernel and a full connection table = "fully connected layers" really act as 1x1 convolutions = ConvNets에 굳이 fixed-sized input이 요구될 필요가 없음
- 즉, FC 계층에 들어가는 feature map의 크기를 고정시키기 위한 노력이 불필요하다고 해석함. 따라서, 입력 이미지의 크기가 다를 경우, slide를 조절하여, 일정한 resolution으로 크기가 들어오도록 조절 가능하고, voting을 통해 판단함.





